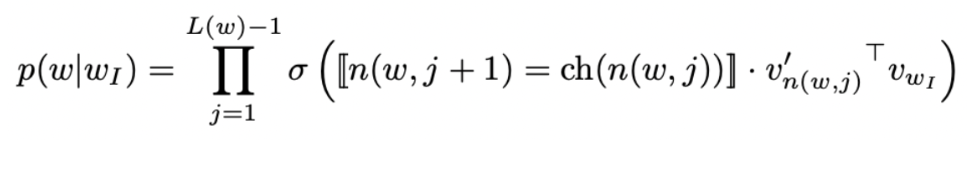출처 : https://arxiv.org/pdf/1607.01759.pdf
초록
위 논문은 텍스트 분류를 위한 간단하고 효과적인 baseline을 탐구한다. 우리의 실험은 fastText라는 빠른 text classifier가 학습과 평가에서 다른 딥러닝 분류기들과 비슷한 정확도를 보임과 동시에 속도가 빠름을 보여준다. 멀티 코어 CPU로 1억개의 단어들을 십분안에 학습할 수 있고 5000개의 문장들을 312000개의 클래스로 일분 안에 분류할 수 있다.
1. Introduction
텍스트 분류는 NLP에서 매우 중요한 작업이다(가령, 웹 검색, 정보 탐색, ranking and document classification 등) 최근에 신경망을 기반으로 한 모델들이 매우 인기있다. 이러한 모델들이 실전에서 좋은 성능을 보이긴 하지만, train과 test에서 상대적으로 느리며 매우 큰 데이터셋을 사용하기에 힘들다.
한편, linear classifier은 텍스트 분류 문제에 대한 강력한 baseline으로 여겨진다. 그들의 단순함에도 불구하고, 올바른 feature들이 주어지면, 좋은 성능을 보여주며 매우 많은 corpus를 처리할 수 있는 가능성 또한 있다.
위 논문에서, 우리는 텍스트 분류의 맥락에서 많은 output 차원을 가진 거대 corpus를 scale할 수 있는 방법들을 탐구하고자 한다. 최근 효과적인 word representation learning에 감명받아, 우리는 rank constraint 와 fast loss approximation을 갖고 있는 linear model들이 최신 기술들과 비슷한 정확도를 보이며 10분 안에 1억개의 단어들을 학습할 수 있음을 보여주려 한다. 우리는 fastText를 tag prediction과 sentiment analysis 두가지 task에 활용하여 평가하고자 한다.
2. Model Architecture
문장 분류를 위한 간단하고 효율적인 baseline은 문장들을 bag of Words(boW)로 표현하고 linear classifier(가령, logistic regression 혹은 Support Vector Machine)에 학습시키는 것이다. 그러나, linear classifier들은 feature와 class 간에 파라미터를 공유하지 않기에, output차원이 클 때에는 일반화가 잘 이루어지지 않는다.(어떤 클래스들은 매우 작은 예시만을 갖기에) 이 문제를 해결하기 위한 일반적인 solution으로 linear classifier를 낮은 rank matrices로 분해하거나 multilayer-neural-networs를 사용하는 것이다.
Figure 1은 rank constraint가 포함된 간단한 선형 모델을 보여준다. 첫번째 weight matrix인 A는 단어에 대한 look-up table이다. word representations들은 이후 text representation으로 평균화되는데, 그 이후에 linear classifier에 부여된다. Text representation은 잠재적으로 사용 가능한 hidden variable에 해당한다. 이 구조는 중간 단어가 label에 의해 대체되어 있는 cbow 모델과 비슷하다. 우리는 softmax 함수인 f를 이용하여 이미 정해진 classes에 대해 확률 분포를 계산하고자 한다. N documents의 셋에서 negative log likelihood를 각 클래스 별로 최소화하고자 한다. 이는 다음과 같다.

이 모델은 multiple CPUs에서 동시적으로 학습되었으며 stochastic gradient descent와 lineary decaying learning rate를 이용하여 학습되었다.
2.1 Hierarchical Softmax
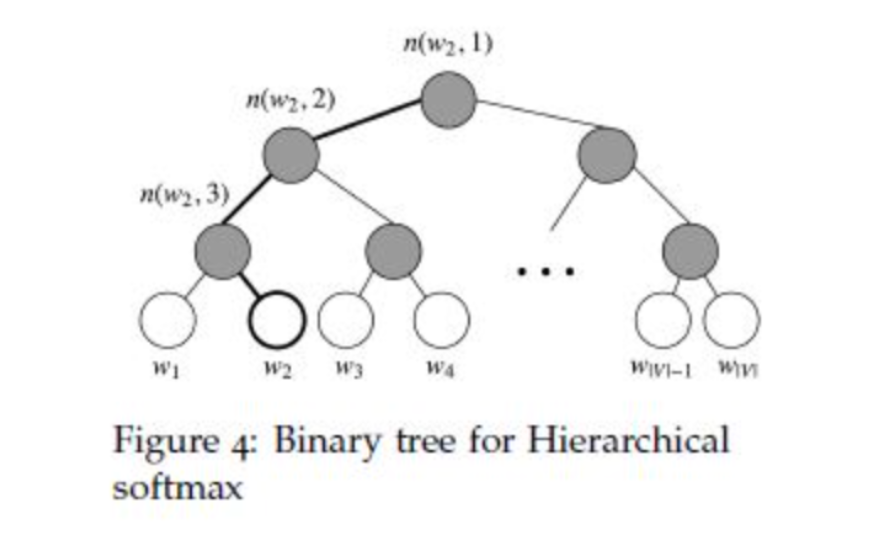
클래스가 많을 때, linear classifier를 계산하는 것은 큰 비용이 든다. 정확하게 말하자면, 계산 복잡도는 O(kh)인데, 이때 k는 클래스의 개수를, h는 text representation의 차원의 수를 말한다. running time을 개선하기 위하여 hierarchical softmax를 사용한다. 학습 시에 계산 복잡도는 O(hlog2(k))로 떨어진다.
Hierarchical softmax는 가장 그럴듯한 클래스를 찾는 test 시에도 유용하다. 각 노드는 루트에서 해당 노드로 오기까지 path의 확률로 연관된다. 만약 l+1 깊이의 노드가 부모 노드들이 n1, n2, .., nl 까지 있다면, 확률은 각 부모 노드의 확률을 모두 곱하는 것과 같다. 이는 자식 노드가 부모 노드보다 확률이 더 낮음을 의미한다. 깊이 우선 탐색으로 트리를 탐색하고 잎 노드 사이에서 최대 확률을 추적하여 작은 확률과 연관된 가지들은 버릴 수 있게 된다. (깊이 우선 탐색 : 자기 자신을 호출하는 순회 알고리즘으로 이웃 노드를 탐색하는 과정에서 가장 깊은 노드까지 탐색한 이후 backtracing 하며 방문하지 않은 노드 방문). 실제로, 우리는 test 시에 복잡도가 O(hlog2(k))로 감소하는 것을 발견했다. 이 접근은 binary heap(이진 힢)을 사용하여 T개의 top target들을 O(logT)의 복잡도로 계산할 수 있게 한다.
2.2 N-gram features
Bag of Words는 어순을 고려하지 않지만 단어의 어순을 고려하는 것은 컴퓨팅 비용이 비싸다. 대신, 우리는 bag of n-grams를 사용하여 주변 단어의 어순의 부분적인 정보를 고려할 수 있도록 하였다. 이 방법은 실전에서 매우 효율적이었고 어순을 사용하는 방법들과 견줄만한 결과를 성취해냈다. 우리는 hashing trick을 이용하여 n-gram을 빠르고 메모리 효율적으로 매핑하였고 bigram을 사용했을 때는 10M개의 bins와 Mikolov et al.에서 나온 해싱 함수와 동일한 함수를 사용했다.
3 Expremients
우리는 fastText를 두개의 다른 task 들에서 평가했다. 우선, 우리는 감정 분석의 문제에 대한 존재하는 텍스트 분류기들을 이것과 비교했다. 그리고 나서, 우리는 tag prediction dataset에 큰 output space로 스케일하는 능력을 평가했다. 우리의 모델이 Vowpal Wabbit library와 함께 실행될 수 있었고, 실전에서 우리의 실험은 적어도 2배에서 5배정도 빨랐다.
3.1 감정 분석 실험과 결과
기존의 모델들인 BoW, ngrams, ngrams TFIDF, char-CNN, char-CRNN, VDCNN 등의 모델들과 fastText를 비교하였고 결과적으로, 정확도는 char-CNN와 char-CRNN보다 살짝 높았고 VDCNN보다 살짝 낮았다. 더 많은 n-grams를 이용함으로써 정확도가 더욱 높아짐 또한 확인할 수 있었다. 또한, Tang et al(2015)의 방법들과 비교해봤을 때 fastText역시 경쟁력이 있음을 알 수 있었다. 또한 학습속도 역시 굉장히 빨랐다!
3.2 태그 예측
제목과 자막에 따라 태그를 예측하는 것에 초점을 맞추었고 Tagspace라는 모델(Convolution 기반)과 비교하였다. 결과적으로 속도도 더 빨랐고 더 정확했다!
4.Discussion
딥러닝 모델들이 최근 엄청난 인기를 얻고 있긴 하지만, 선형모델을 기반으로 한 Fasttext역시 성능이 그와 비슷한 반면 더욱 빨랐다.
'NLP' 카테고리의 다른 글
| [논문리뷰] Distributed Representations of Words and Phrases and their Compositionality (0) | 2023.03.12 |
|---|---|
| [논문 리뷰]NNLM(A Neural Probabilistic Language Model) (0) | 2023.03.02 |
| Weekly NLP(~week9) (0) | 2023.02.06 |
| BoW 모델 구현 (0) | 2022.10.02 |
| N-Gram 모델 구현하기 (0) | 2022.09.29 |