One-hot-vectors : 단어를 Nx1 Column Vector로 표현
Scalar(스칼라) : 숫자
Vector(벡터) : 방향+숫자
Euclidean Space : Vector의 차원
Word Embedding (워드 임베딩) : 단어 간의 관계를 학습하여 Vector에 저장하는 모델
One-hot-vectors는 Vocabularary가 무한정 커질 수 있기에 비효율적이다. word2vec과 GloVe는 vocabulary의 차원을 낮추려고 함. word embedding은 단어 간의 관계 입력 + 차원 감소
- GloVe : 문장에 한 단어가 어떤 근처 단어들과 몇번을 같이 나오는지 세는 Co-Occurence matrix 활용.
- ex) 전체 Corpus에 40000개의 단어 존재. 40000x40000 Matrix를 만들고 붙어 있는 단어의 빈도수 마다 matrix의 숫자 증가. 이후 Singular Value Decomposition(SVD)를 활용하여 차원을 300x40000으로 감소.
- Word2Vec : Continuous bow혹은 Skipgram알고리즘을 활용하여 단어 간의 관계 학습. cbow는 주변 단어가 주어졌을 때 타깃 단어를 예측하는 모델. Skipgram은 타깃 단어가 주어졌을 때 주변 단어를 예측하는 모델. 예측을 위해 Neural Network를 활용하고 Stochastic Gradient Descent(SGD)를 통해 학습한다. Input에는 Nx1 word embedding이 들어감.
BOW와 TF-IDF는 단어의 빈도수를 계산하여 N차원의 열벡터로 문장을 표현
Word Embedding은 GloVe 혹은 Word2Vec같은 알고리즘으로 벡터의 차원을 줄이고 N차원 공간의 하나의 점으로 바꾸어 표현
- Eucliedian Distance

- Cosine Similarity

- Cosine Distance = 1 - Cosine similarity
NLP에서는 단어의 빈도수를 다루기 때문에 Cosine similarity가 주로 많이 사용됨. 벡터들 간의 유사성을 계산할 때는 Cosine distance가 사용됨.
Text Classification
- Binary Classification : 긍정 혹은 부정으로 분류. Logistic Regression Classifier = Linear Regression+Sigmoid
- Feature Importance : 모델이 중요하게 생각하는 단어
Multinomial Naive Bayes Classifier

위의 P(c|d)는 베이즈 정리를 통해 변형될 수 있음.

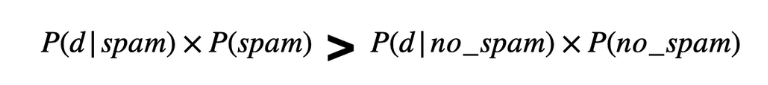
NLP에서도 CNN 사용가능. word embedding은 단어를 column vector로 표현하지만 row vector로 변환하여 단어 순서대로 차례로 row vector들을 쌓음. 이후 1D 필터를 통해 학습. 이는 감정분석, 질문 유형 분석, 객관/주관 유형 분석에서 뛰어난 성능.
Pretrain worde embedding은 알고리즘을 이용하여 많은 데이터를 학습한 결과물. transfer learning이라고도 함.
'NLP' 카테고리의 다른 글
| [논문리뷰] Distributed Representations of Words and Phrases and their Compositionality (0) | 2023.03.12 |
|---|---|
| [논문 리뷰]NNLM(A Neural Probabilistic Language Model) (0) | 2023.03.02 |
| BoW 모델 구현 (0) | 2022.10.02 |
| N-Gram 모델 구현하기 (0) | 2022.09.29 |
| 텍스트 분석과 토큰화 (0) | 2022.09.28 |